In seinem Vortrag “Freedom in the cloud” (Audio und Video zum Download hier, Video bei Youtube hier und hier, Transkript hier) im Mai und dem Folgevortrag bei der Debconf im August hat Eben Moglen eigentlich vor allem darüber geredet, wie zukünftig die de-facto Server-Client-Struktur des Netzes zur ursprünglich gedachten “network of peers” zurückgeführt werden muss, um Freiheit zu ermöglichen.
Dabei kam aber ein spannendes Nebenprodukt heraus, das ich hier einmal kurz beleuchten möchte. Moglen hat vorgeschlagen, dass wir das Konzept “Privatsphäre” neu denken müssen:
They still think of privacy as “the one secret I don’t want revealed” and that’s not the problem. Their problem is all the stuff […] that they don’t think of as secret in any way but which aggregates to stuff that they don’t want anybody to know. Which aggregates, in fact, not just to stuff they don’t want people to know but to predictive models about them that they would be very creeped out could exist at all.
Die “they”, von denen er spricht, sind seine Jura-Studenten, die benutzt er aber in diesem Teil des Vortrags als Äquivalent für “Selbst Leute, die drüber nachgedacht haben müssten”.
Sinngemäße Übersetzung:
Sie verstehen unter Privatsphäre immer noch “Das eine Geheimnis, dass ich bewahren möchte.” Und dieses eine Geheimnis ist nicht das Problem. Das Problem sind all […] die Informationen, die sie nicht als geheim erachten, aber die zu Informationen zusammengeführt werden können, von denen sie nicht möchten, das jemand anders sie weiß. Die sogar zu Vorhersagemodellen über sie zusammengeführt werden können, wo sie sich gruseln würden, dass diese überhaupt existieren können.
Das Prinzip hinter dieser Zusammenführung ist einfach: Wenn ich genug weiß, kann ich durch Schlussfolgern auch die Lücken füllen, über deren Inhalt ich nichts weiß. Jeder, der schon mal ein Sudoku-Rätsel gelöst hat, kennt das.
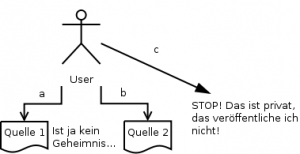 Übertragen auf unser gesellschaftliches Leben mit dem Netz bedeutet das, dass ein Nutzer zwar entscheiden kann, dass er Information a irgendwo angibt (Quelle 1), weil sie kein Geheimnis ist. Dass er wo anders (Quelle 2) Information b angibt, weil sie kein Geheimnis ist usw. Information c gibt er nicht her, weil er sie als geheim/privat betrachtet.
Übertragen auf unser gesellschaftliches Leben mit dem Netz bedeutet das, dass ein Nutzer zwar entscheiden kann, dass er Information a irgendwo angibt (Quelle 1), weil sie kein Geheimnis ist. Dass er wo anders (Quelle 2) Information b angibt, weil sie kein Geheimnis ist usw. Information c gibt er nicht her, weil er sie als geheim/privat betrachtet.
Soweit so gut. Wenn jetzt aber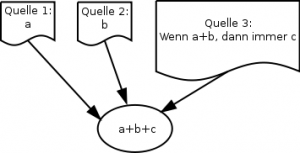 jemand sowohl Zugang zu Quelle a, als auch zu Quelle b hat und aus einer dritten Quelle (die durchaus auch allgemein bekannt sein kann) noch die Information hat, dass wenn a und b zusammen auftreten immer auch c gilt, dann ist es um die Geheimhaltung von c geschehen.
jemand sowohl Zugang zu Quelle a, als auch zu Quelle b hat und aus einer dritten Quelle (die durchaus auch allgemein bekannt sein kann) noch die Information hat, dass wenn a und b zusammen auftreten immer auch c gilt, dann ist es um die Geheimhaltung von c geschehen.
Nun könnte man sagen: “Der Idiot, was gibt der auch Informationen preis, von denen er weiß, dass man private/geheime Informationen schlussfolgern kann!”
Und genau das ist der Knackpunkt. Das weiß er womöglich nicht. Und zwar aus 3 Gründen:
- Weiß er womöglich nicht, dass jemand Quelle 1 und Quelle 2 zusammenführen kann.
- Weiß er womöglich nicht, dass man aus a und b -> c herleiten kann.
- Ist das System aus Informationen womöglich deutlich komplexer als obiges Beispiel.
Solange noch alles wenig komplex ist, bleibt es für den Menschen noch überschaubar (Sudokus bewegen sich naturgemäß im Grenzbereich dieser Überschaubarkeit). Aber irgendwann wird die Komplexität der Zusammenhänge so hoch, dass es unmöglich wird, ohne Hilfe von Computern und/oder bestimmten Algorithmen einzuschätzen, auf welche Informationen sich aus den vorhandenen Daten schließen lässt.
Und genau an diesem Level an Komplexität sind wir angekommen. Wir platzieren einzelne Informationen, die kein Geheimnis sind, an unterschiedlichen Stellen und können ohne Computer nicht mehr einschätzen, ob sich mit Computern weitere Informationen daraus ableiten lassen.
Es gibt dafür praktische Beispiele. So hat eine Gruppe von Studenten am MIT nachgewiesen, dass man in Facebook homosexuelle Männer durch Analyse ihrer Facebook-Friends als Homosexuelle identifizieren kann, auch wenn sie diese Information nicht im Profil preisgegeben haben.
Wenn man jetzt noch berücksichtigt, dass wir hier nicht nur über 100%ig sichere Schlussfolgerungen reden, sondern auch über mit Mitteln der Inferenzstatistik gewonnene Schlussfolgerungen, kann man wirklich nicht mehr davon ausgehen, dass der User noch wirklich abschätzen kann wie viel er tatsächlich von sich preisgibt, wenn er nur ein kleines bisschen von sich preisgibt.
Dazu kommt noch, dass es ja nicht nur der User selbst ist, der Informationen über sich ins Netz gibt, sondern auch andere Personen. Zwei Beispiele:
- Wenn jemand bei Facebook das berühmt-berüchtigte Partyfoto hochlädt, dass nicht nur ihn selbst, sondern auch andere Personen zeigt, dann hat dieser jemand Daten über die anderen Personen verfügbar gemacht, womöglich ohne, dass diese Personen davon Kenntnis haben oder erlangen können.
- Wenn jemand durch Nutzung von Google Mail der Firma Google erlaubt, den Inhalt seiner Mails vollautomatisch semantisch zu analysieren, dann erlaubt er dies auch für alle, mit denen er per Mail korrespondiert
Eben Moglen hat also recht: Wir müssen die Privatsphäre neu denken. Nicht nur die einzelnen Informationen, die wir veröffentlichen, gilt es zu bedenken, sondern auch die daraus herleitbaren Informationen (die wir womöglich selbst nichts haben…).
Daraus resultieren Konsequenzen für das Verhalten der User und für die Politik:
Auf politischer Seite muss
- das Datenschutzrecht modifiziert werden, so dass das Zusammenführen von Daten genauso zustimmungspflichtig wird, wie jetzt schon das Speichern neuer Daten. Ähnlich fordert das der CCC in seinen Forderungen für ein lebenswertes Netz :
Daher soll datenschutzrechtlich dafür gesorgt werden, daß auch jemand, der legal Zugriff auf mehrere Datenbanken hat, daraus für ihn nicht das Recht auf Zusammenführung der Daten folgt.
- eine Möglichkeit geschaffen werden, mit denen der User erfährt, wer welche Daten über ihn gespeichert hat. Bisher geschieht dies nur auf Nachfrage. Um jemanden Fragen zu können muss man aber zumindest wissen, dass dieser jemand überhaupt Daten über einen hat. Eine Möglichkeit, wie dies geschehen könnte beschreibt der CCC in seiner Forderung nach einem Datenbrief.
Im Verhalten der User
- ist eine generelle Vorsicht bei der Abgabe von Daten vonnöten, die sich immer am funktionalen Minimum orientiert, also an der Frage: was ist die kleinstmögliche Menge an Daten, die ich einem Serviceanbieter geben muss, damit ich den Service erfolgreich nutzen kann.
- sind dezentral organisierte Dienste immer zu bevorzugen.
- ist wo immer möglich Verschlüsselung anzuwenden.
- sind Sätze wie “Ich hab nichts zu verbergen.” völlig aus dem Wortschatz zu streichen.
![]()