Ich mach jetzt auch mal dieses PostPrivacy-Dingens.
Mein Kind:

Ich mach jetzt auch mal dieses PostPrivacy-Dingens.
Mein Kind:
Jenseits dessen, was Wikileaks veröffentlicht hat, entlarvt der Umgang von Regierungen und Presse mit ihnen viele Strukturen und Denkweisen.
Ob der Vorschlag von Sarah Palin, Assange zu töten, das massive Vorgehen des erklärten Whistleblowing-Befürworters Obama gegen Whistleblower in US-Behörden oder wie leicht Firmen wie Amazon, Paypal oder Banken sich zu Erfüllungsgehilfen von Regierungen machen. Und natürlich nicht zu vergessen, wie sich das Vorgehen der schwedischen Strafverfolgung veränderte, als das amerikanische und öffentliche Interesse an Assange stieg.
Jetzt reiht sich auch Twitter in den Reigen ein und gibt Nutzerdaten von Wikileaks-Unterstützern an die US-Regierung heraus. Aus Betroffenen-Perspektive hat Rop Gonrijp das sehr ausführlich geschildert.
Das zeigt nicht nur, dass auch Twitter bereitwillig kooperiert, sondern auch, dass wir beim Neudenken unserer Privatsphäre die Unternehmen als Gefahrenquelle nicht ignorieren dürfen. Das Argument, dass Facebook, Google und Co. uns nicht als Kunden verlieren möchten und deshalb nichts gegen unsere Interessen mit unseren Daten anstellen ist m.E. für sich schon wackelig. Twitters bereitwillige Herausgabe von Daten zeigt aber darüber hinaus, dass wir auch mitdenken müssen, was jene, denen die Unternehmen die Daten aushändigen, damit machen.
![]()
In seinem Vortrag “Freedom in the cloud” (Audio und Video zum Download hier, Video bei Youtube hier und hier, Transkript hier) im Mai und dem Folgevortrag bei der Debconf im August hat Eben Moglen eigentlich vor allem darüber geredet, wie zukünftig die de-facto Server-Client-Struktur des Netzes zur ursprünglich gedachten “network of peers” zurückgeführt werden muss, um Freiheit zu ermöglichen.
Dabei kam aber ein spannendes Nebenprodukt heraus, das ich hier einmal kurz beleuchten möchte. Moglen hat vorgeschlagen, dass wir das Konzept “Privatsphäre” neu denken müssen:
They still think of privacy as “the one secret I don’t want revealed” and that’s not the problem. Their problem is all the stuff […] that they don’t think of as secret in any way but which aggregates to stuff that they don’t want anybody to know. Which aggregates, in fact, not just to stuff they don’t want people to know but to predictive models about them that they would be very creeped out could exist at all.
Die “they”, von denen er spricht, sind seine Jura-Studenten, die benutzt er aber in diesem Teil des Vortrags als Äquivalent für “Selbst Leute, die drüber nachgedacht haben müssten”.
Sinngemäße Übersetzung:
Sie verstehen unter Privatsphäre immer noch “Das eine Geheimnis, dass ich bewahren möchte.” Und dieses eine Geheimnis ist nicht das Problem. Das Problem sind all […] die Informationen, die sie nicht als geheim erachten, aber die zu Informationen zusammengeführt werden können, von denen sie nicht möchten, das jemand anders sie weiß. Die sogar zu Vorhersagemodellen über sie zusammengeführt werden können, wo sie sich gruseln würden, dass diese überhaupt existieren können.
Das Prinzip hinter dieser Zusammenführung ist einfach: Wenn ich genug weiß, kann ich durch Schlussfolgern auch die Lücken füllen, über deren Inhalt ich nichts weiß. Jeder, der schon mal ein Sudoku-Rätsel gelöst hat, kennt das.
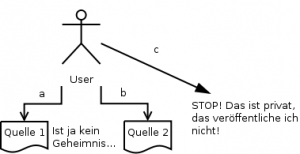 Übertragen auf unser gesellschaftliches Leben mit dem Netz bedeutet das, dass ein Nutzer zwar entscheiden kann, dass er Information a irgendwo angibt (Quelle 1), weil sie kein Geheimnis ist. Dass er wo anders (Quelle 2) Information b angibt, weil sie kein Geheimnis ist usw. Information c gibt er nicht her, weil er sie als geheim/privat betrachtet.
Übertragen auf unser gesellschaftliches Leben mit dem Netz bedeutet das, dass ein Nutzer zwar entscheiden kann, dass er Information a irgendwo angibt (Quelle 1), weil sie kein Geheimnis ist. Dass er wo anders (Quelle 2) Information b angibt, weil sie kein Geheimnis ist usw. Information c gibt er nicht her, weil er sie als geheim/privat betrachtet.
Soweit so gut. Wenn jetzt aber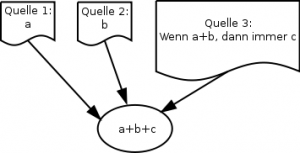 jemand sowohl Zugang zu Quelle a, als auch zu Quelle b hat und aus einer dritten Quelle (die durchaus auch allgemein bekannt sein kann) noch die Information hat, dass wenn a und b zusammen auftreten immer auch c gilt, dann ist es um die Geheimhaltung von c geschehen.
jemand sowohl Zugang zu Quelle a, als auch zu Quelle b hat und aus einer dritten Quelle (die durchaus auch allgemein bekannt sein kann) noch die Information hat, dass wenn a und b zusammen auftreten immer auch c gilt, dann ist es um die Geheimhaltung von c geschehen.
Nun könnte man sagen: “Der Idiot, was gibt der auch Informationen preis, von denen er weiß, dass man private/geheime Informationen schlussfolgern kann!”
Und genau das ist der Knackpunkt. Das weiß er womöglich nicht. Und zwar aus 3 Gründen:
Solange noch alles wenig komplex ist, bleibt es für den Menschen noch überschaubar (Sudokus bewegen sich naturgemäß im Grenzbereich dieser Überschaubarkeit). Aber irgendwann wird die Komplexität der Zusammenhänge so hoch, dass es unmöglich wird, ohne Hilfe von Computern und/oder bestimmten Algorithmen einzuschätzen, auf welche Informationen sich aus den vorhandenen Daten schließen lässt.
Und genau an diesem Level an Komplexität sind wir angekommen. Wir platzieren einzelne Informationen, die kein Geheimnis sind, an unterschiedlichen Stellen und können ohne Computer nicht mehr einschätzen, ob sich mit Computern weitere Informationen daraus ableiten lassen.